Введение Engram: Инновационная память для разреженных LLM
DeepSeek представляет Engram, улучшая эффективность LLM с помощью условной оси памяти.
Понимание ограничений трансформеров
Трансформеры полагаются на внимание и Mixture-of-Experts (MoE) для масштабирования, но им не хватает эффективного механизма поиска знаний. Это приводит к повторным вычислениям одних и тех же локальных паттернов, что приводит к потере глубины и FLOPs. Модуль Engram от DeepSeek решает эту проблему, внедряя условную ось памяти, которая дополняет MoE вместо замены.
Engram: Современное решение
Engram оживляет классические N-граммные встраивания, предоставляя масштабируемую O(1) память для поиска, которая без проблем интегрируется в основу трансформера. Она предлагает параметрическую память, способную хранить статические паттерны, такие как общие фразы и сущности, позволяя основной архитектуре сосредоточиться на сложном рассуждении и взаимодействиях на дальнем расстоянии.
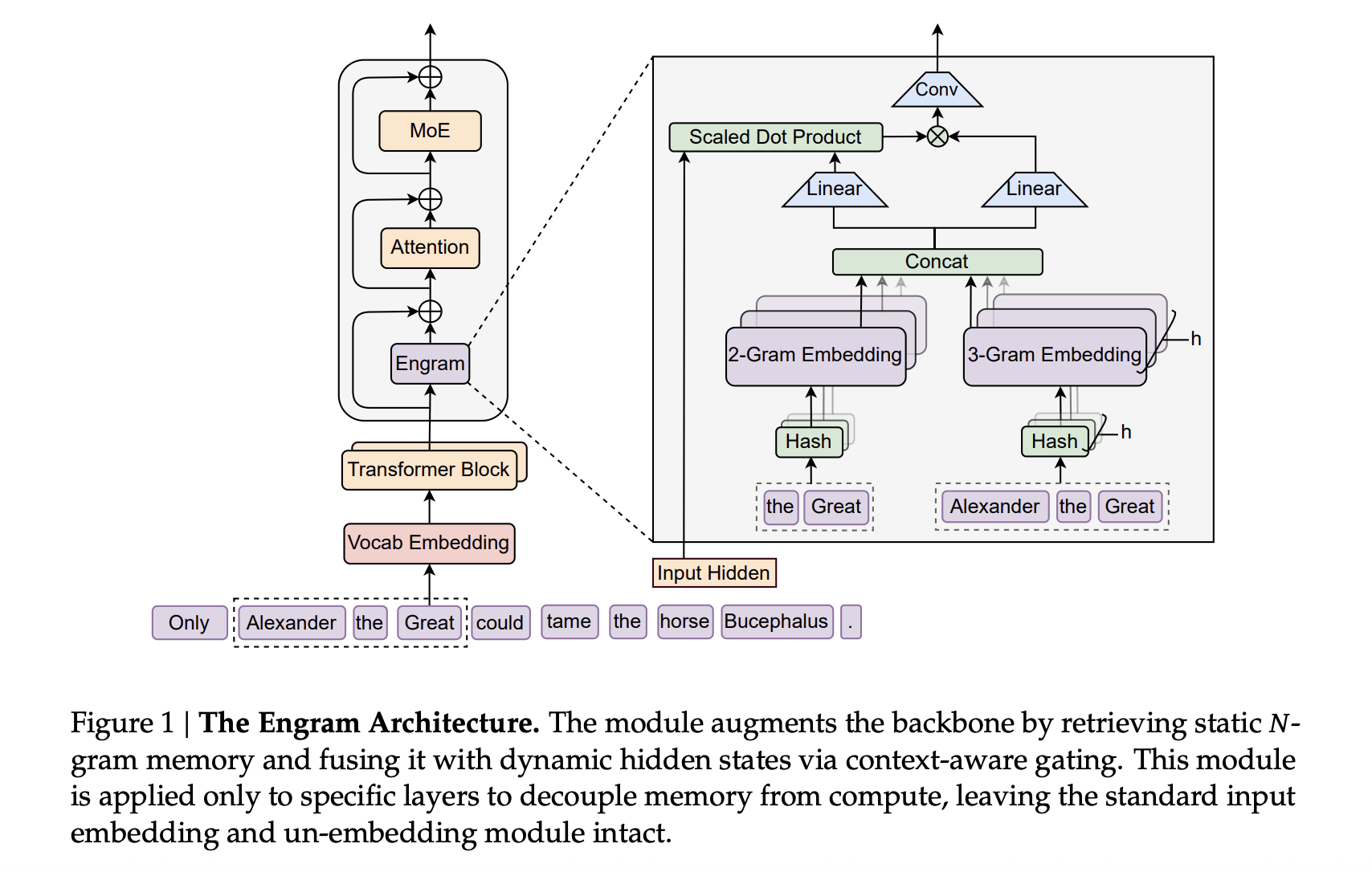
Интеграция Engram в трансформеры DeepSeek
Подход Engram использует токенизатор DeepSeek V3 с 128k словарем, преподготавливая на 262B токенах. Основа включает 30-блоковый трансформер с размером скрытого состояния 2560 и капитализирует на Multi-head Latent Attention с 32 головами, оптимизируя с помощью оптимизатора Muon.
Engram функционирует как модуль разреженного встраивания, построенный на основе хешированных N-граммных таблиц. Каждый контекст N-грамм проходит через глубинную свертку, а механизм управления контролирует инъекцию встраивания. Модели большого масштаба, такие как Engram-27B и Engram-40B, разделяют архитектуру трансформера с MoE-27B, корректируя параметры для поддержания эффективности с уменьшенным количеством маршрутизируемых экспертов.
Распределение разреженности: Тонкий баланс
Распределение разреженных параметров между маршрутизируемыми экспертами и Engram определяет проблему распределения разреженности. Исследования показывают оптимальное разделение между экспертами MoE и памятью Engram для повышения производительности моделей, подтверждая, что эти компоненты работают лучше всего при эффективном балансе.
Результаты предварительной подготовки
Engram-27B и Engram-40B последовательно превосходят базу MoE-27B в различных тестах, включая языковое моделирование и задачи по рассуждению. Результаты показывают значительное уменьшение потерь валидации, указывая на эффективность интеграции знаний через Engram.
Возможности длительного контекста и производительность
Расширенные контекстные окна до 32k токенов также эффективно обрабатывались моделями с использованием Engram, что привело к значительным улучшениям в задачах, требующих понимания более длинного контекста.
Ключевые выводы
- Улучшенная память: Engram вводит эффективную память для частых N-граммных паттернов, чтобы поддержать динамическое рассуждение в LLM.
- Оптимальное распределение ресурсов: Балансировка разреженной емкости между экспертами MoE и Engram приводит к улучшению производительности.
- Передовая эффективность в бенчмарках: Улучшенные возможности в тестах на знание и рассуждение демонстрируют эффективность Engram.
- Улучшения длительного контекста: Engram обеспечивает более высокую производительность в сценариях с длительным контекстом без дополнительных вычислительных затрат.
Для более глубокого изучения исследования, ознакомьтесь с Документом Engram и исследуйте Репозиторий GitHub.
Switch Language
Read this article in English