Google DeepMind представляет Evo-Memory для LLM
DeepMind предлагает Evo-Memory для оптимизации стратегий через повторное использование опыта.
Необходимость повторного использования опыта в LLM
Агенты больших языковых моделей начинают сохранять все, что они видят, но могут ли они на самом деле улучшать свои политики в тестовое время на основе этих опытов, а не просто воспроизводя контекстные окна?
Исследователи из Университета Иллинойс и Google DeepMind предлагают Evo-Memory, потоковый бенчмарк и фреймворк агентов, который нацелен на эту проблему. Evo-Memory оценивает обучение в тестовом режиме с помощью самоэволюционирующей памяти, задавая вопрос, могут ли агенты накапливать и повторно использовать стратегии из непрерывных потоков задач вместо полагания только на статические разговорные логи.
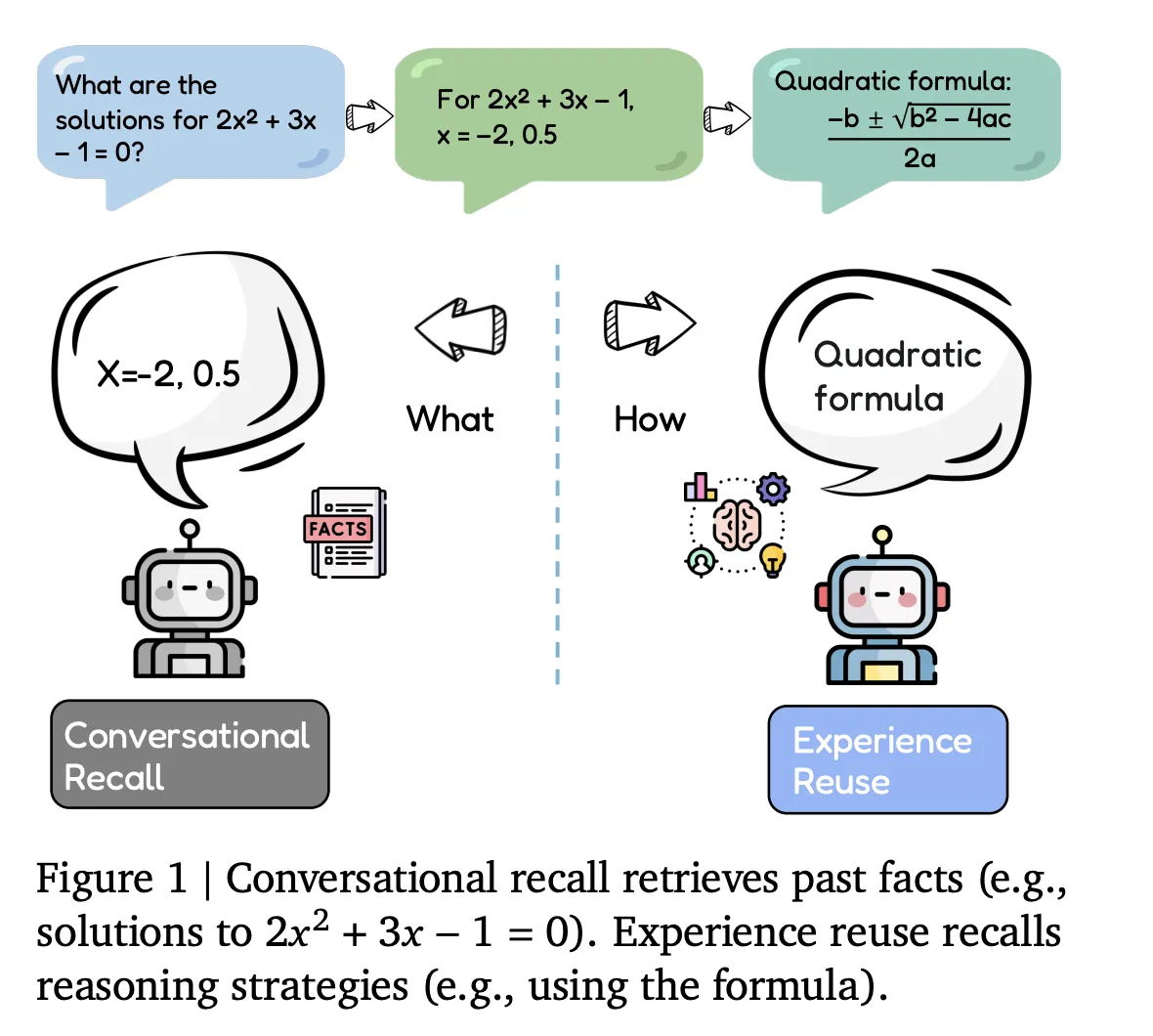
Воспоминание против повторного использования опыта
Большинство текущих агентов реализуют воспоминание о диалоге. Они хранят историю диалогов, следы инструментов и извлеченные документы, которые затем интегрируются в контекстное окно для будущих запросов. Этот тип памяти служит пассивным буфером и не изменяет подход агента к связанным задачам.
Evo-Memory вместо этого сосредоточен на повторном использовании опыта. Каждое взаимодействие рассматривается как опыт, который кодирует не только входные и выходные данные, но также успешность задачи и эффективные стратегии. Бенчмарк оценивает, могут ли агенты извлекать эти опыты позже, применять их как повторно используемые процедуры и со временем уточнять свою память.
Проектирование бенчмарка и потоки задач
Исследовательская группа формализует агента, дополненного памятью, как кортеж ((F, U, R, C)). Базовая модель (F) генерирует выходные данные. Модуль извлечения (R) ищет в хранилище памяти. Конструктор контекста (C) синтезирует рабочий запрос. Функция обновления (U) записывает новые записи опыта и эволюционирует память на каждом шаге.
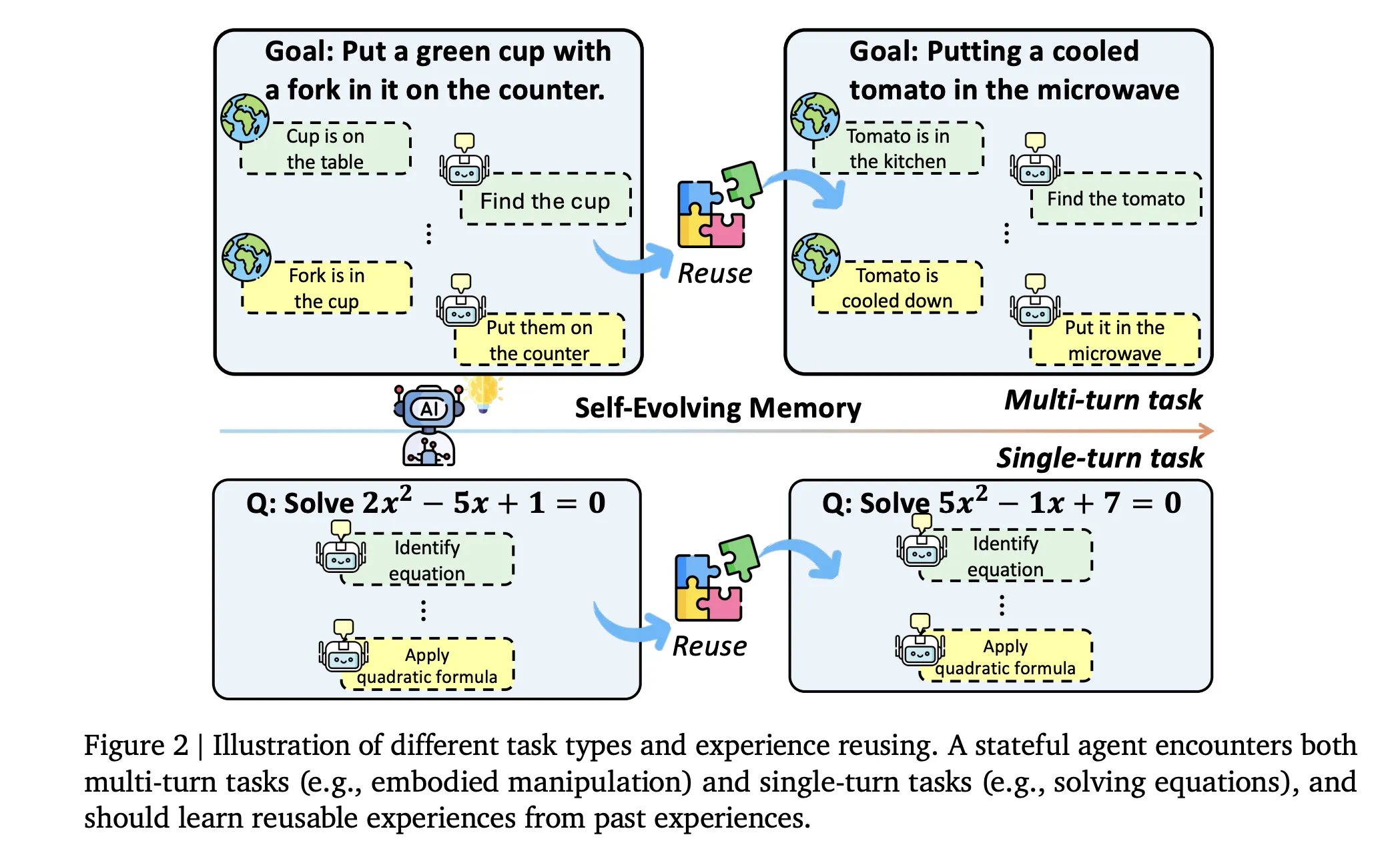
Evo-Memory перестраивает привычные бенчмарки в последовательные потоки задач. Каждый датасет становится упорядоченной последовательностью задач, где ранние элементы содержат стратегии, полезные для последующих. Набор данных охватывает AIME 24, AIME 25, GPQA Diamond и ToolBench.
Оценка выполняется по четырем осям: задачи одного действия используются с точным совпадением или точностью ответа, воплощенные среды измеряют коэффициенты успеха и прогресса, эффективность шага оценивает средний шаг на успешную задачу, а устойчивость последовательности проверяет стабильность производительности при изменении порядка задач.
ExpRAG, минимальные основы повторного использования опыта
Для установления нижней границы группа исследователей представляет ExpRAG. Каждое взаимодействие становится структурированным опытом с шаблоном ⟨xi,yi^,fi⟩, где xi — это вход, yi^ — выход модели, а fi — обратная связь, указывающая на правильность. Агент извлекает похожие опыты и добавляет новые в память без изменения цикла управления.
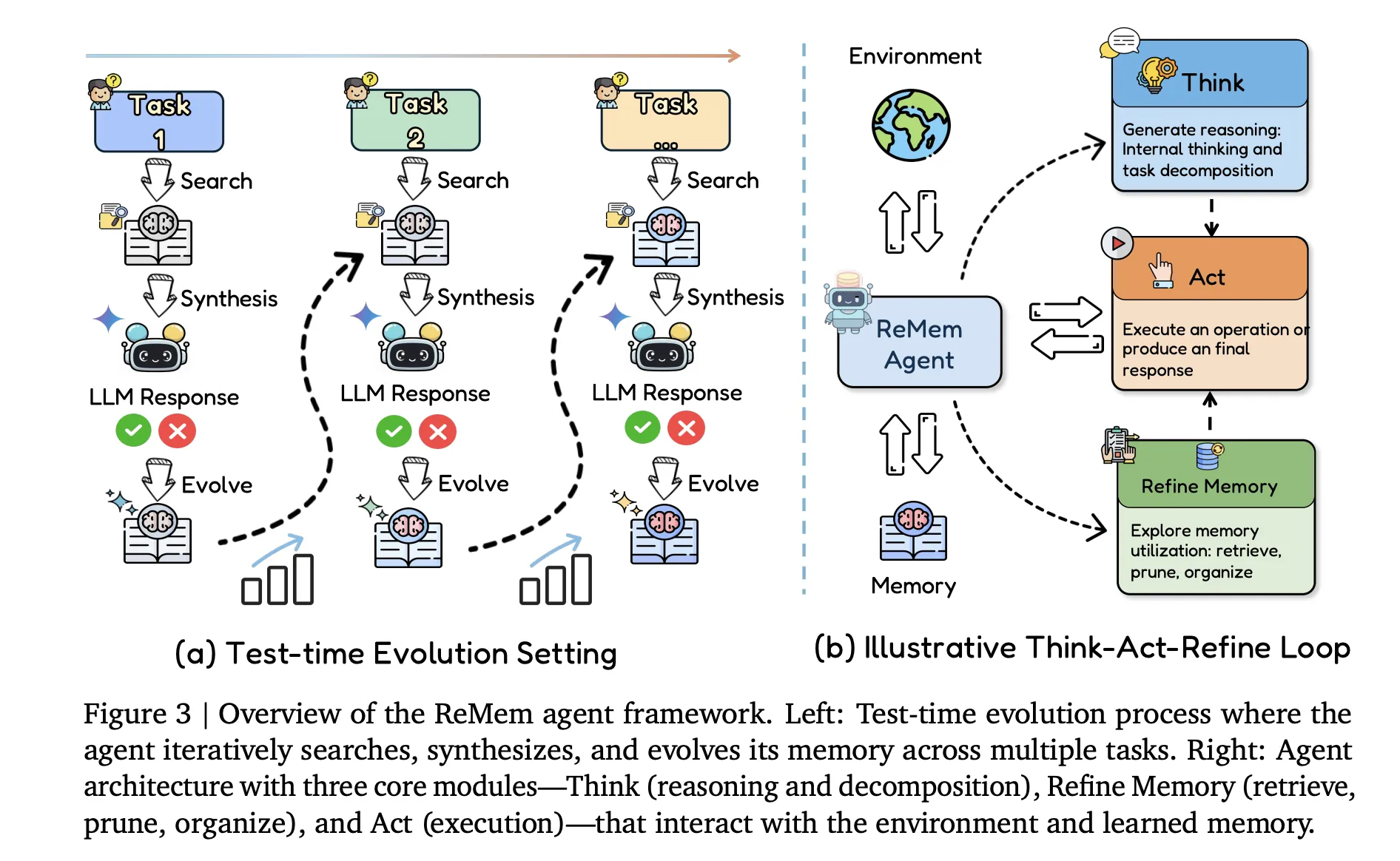
ReMem, действие, размышление, уточнение памяти
Основной вклад на стороне агента делает ReMem, поток, позволяющий агенту выбирать одно из трех действий: Размышление, Действие и Уточнение. Этот цикл создает процесс принятия решений Маркова, где агент активно управляет памятью во время вывода, в отличие от традиционных агентов, которые рассматривают память как фиксированный буфер.
Результаты по логике, инструментам и воплощенным средам
Исследовательская команда оценила все методы на Gemini 2.5 Flash и Claude 3.7 Sonnet в рамках единого протокола, изолируя эффекты архитектуры памяти. Эволюционные методы памяти, такие как ReMem, показали умеренные улучшения во всех бенчмарках.
В многослойных средах ReMem демонстрирует высокую эффективность, значительно повышая коэффициенты успеха по сравнению с базами на истории.
Основные выводы
- Evo-Memory позволяет агентам извлекать и интегрировать память со временем, уходя от статического воспоминания о диалоге.
- Фреймворк формализует агентов как кортеж ((F, U, R, C)) и включает более 10 модулей памяти, оцененных на разнообразных датасетах.
- ExpRAG служит минимальной основой для повторного использования опыта, улучшая производительность по сравнению с традиционными методами, основанными на истории.
- ReMem вводит активное управление памятью во время вывода, что приводит к заметным улучшениям в точности и эффективности.
- Саморазвивающаяся память позволяет меньшим моделям лучше работать без повторного обучения.

Редакционные заметки
Evo-Memory представляет собой значительный шаг вперед в оценке саморазвивающейся памяти в LLM. Исследование эффективно демонстрирует потенциал повторного использования опыта на уровне задач и влияние на производительность агентов без зависимости от фиксированных структур памяти.
Switch Language
Read this article in English