Google DeepMind Unveils Evo-Memory Benchmark for LLMs
DeepMind proposes Evo-Memory for agents to optimize strategies through experience reuse.
The Need for Experience Reuse in LLMs
Large language model agents are starting to store everything they see, but can they actually improve their policies at test time from those experiences rather than just replaying context windows?
Researchers from University of Illinois Urbana Champaign and Google DeepMind propose Evo-Memory, a streaming benchmark and agent framework that targets this exact gap. Evo-Memory evaluates test-time learning with self-evolving memory, asking whether agents can accumulate and reuse strategies from continuous task streams instead of relying only on static conversational logs.
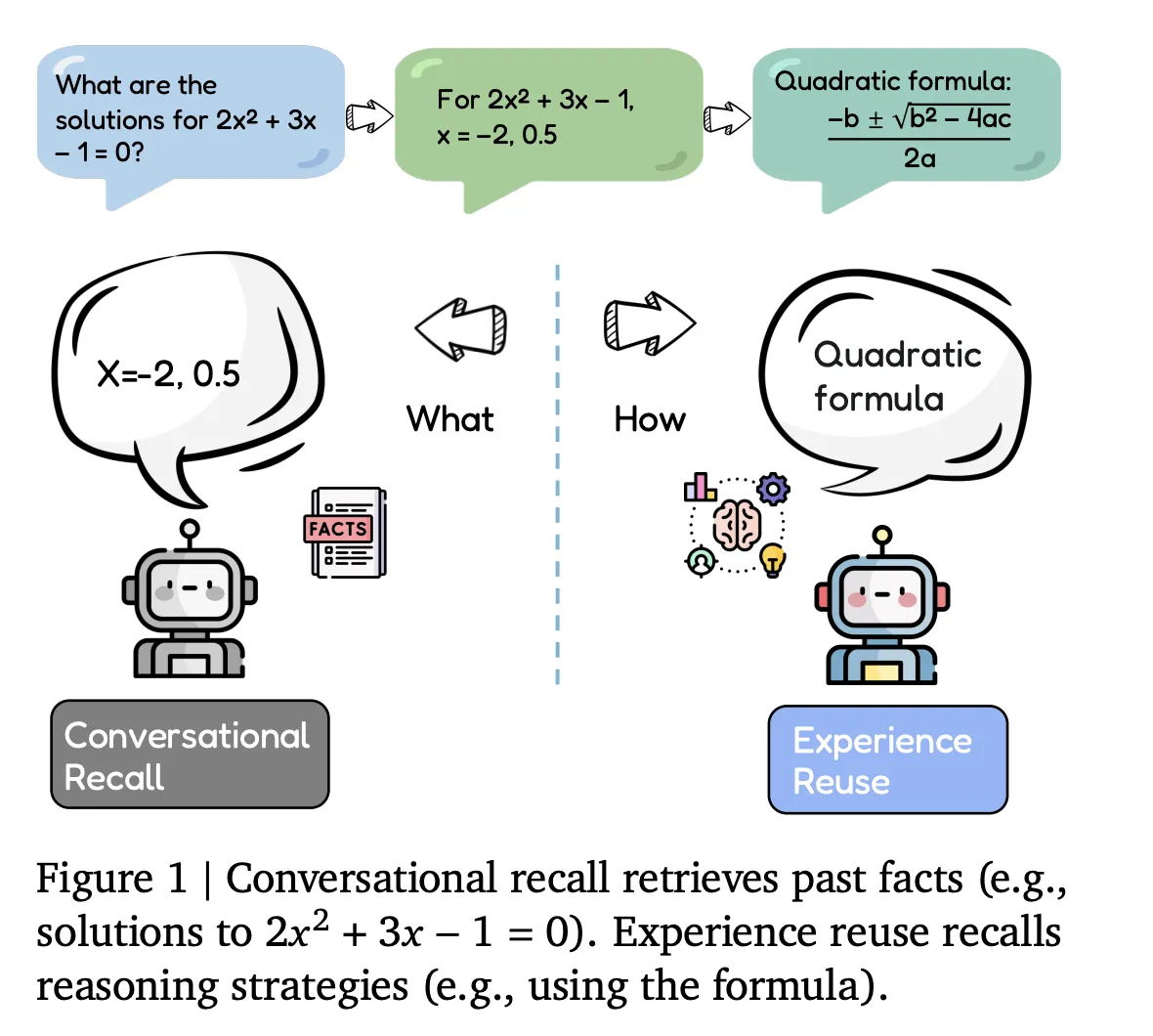
Conversational Recall vs Experience Reuse
Most current agents implement conversational recall. They store dialogue history, tool traces, and retrieved documents, which are then reintegrated into the context window for future queries. This type of memory serves as a passive buffer, recovering facts but not altering the agent’s approach for related tasks.
Evo-Memory focuses on experience reuse. Every interaction is treated as an experience encoding inputs, outputs, success metrics, and effective strategies. The benchmark evaluates agents on their capability to retrieve these experiences later, apply them as reusable procedures, and refine their memory over time.
Benchmark Design and Task Streams
The research team formalizes a memory-augmented agent as a tuple ((F, U, R, C)). Here, the base model (F) generates outputs, the retrieval module (R) searches the memory store, the context constructor (C) synthesizes a working prompt, and the update function (U) writes new experience entries and evolves memory after every step.
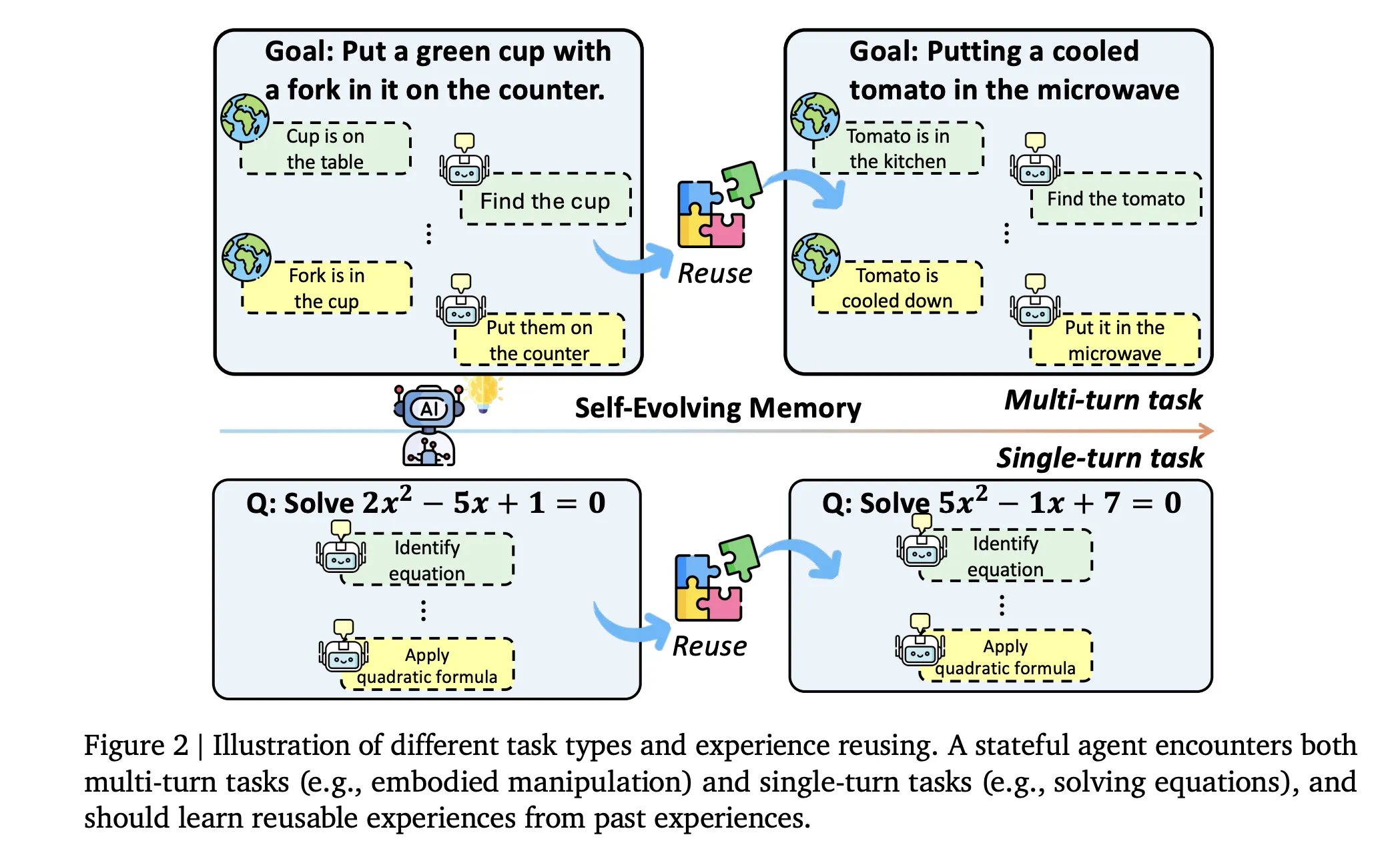
Evo-Memory restructures conventional benchmarks into sequential task streams. Each dataset is an ordered sequence of tasks, where early items provide useful strategies for later tasks. The suite includes diverse datasets like AIME 24, AIME 25, GPQA Diamond, and ToolBench among others.
Evaluation occurs across four axes: single-turn tasks use exact match or answer accuracy, embodied environments measure success and progress rates, step efficiency assesses average steps per successful task, and sequence robustness examines performance stability when task order changes.
ExpRAG, a Minimal Experience Reuse Baseline
To establish a baseline, the research team presents ExpRAG. Each interaction becomes a structured experience text with a template ⟨xi,yi^,fi⟩, where xi is the input, yi^ is the model output and fi is feedback indicating correctness. The agent retrieves similar experiences and appends new ones into memory without changing the control loop.
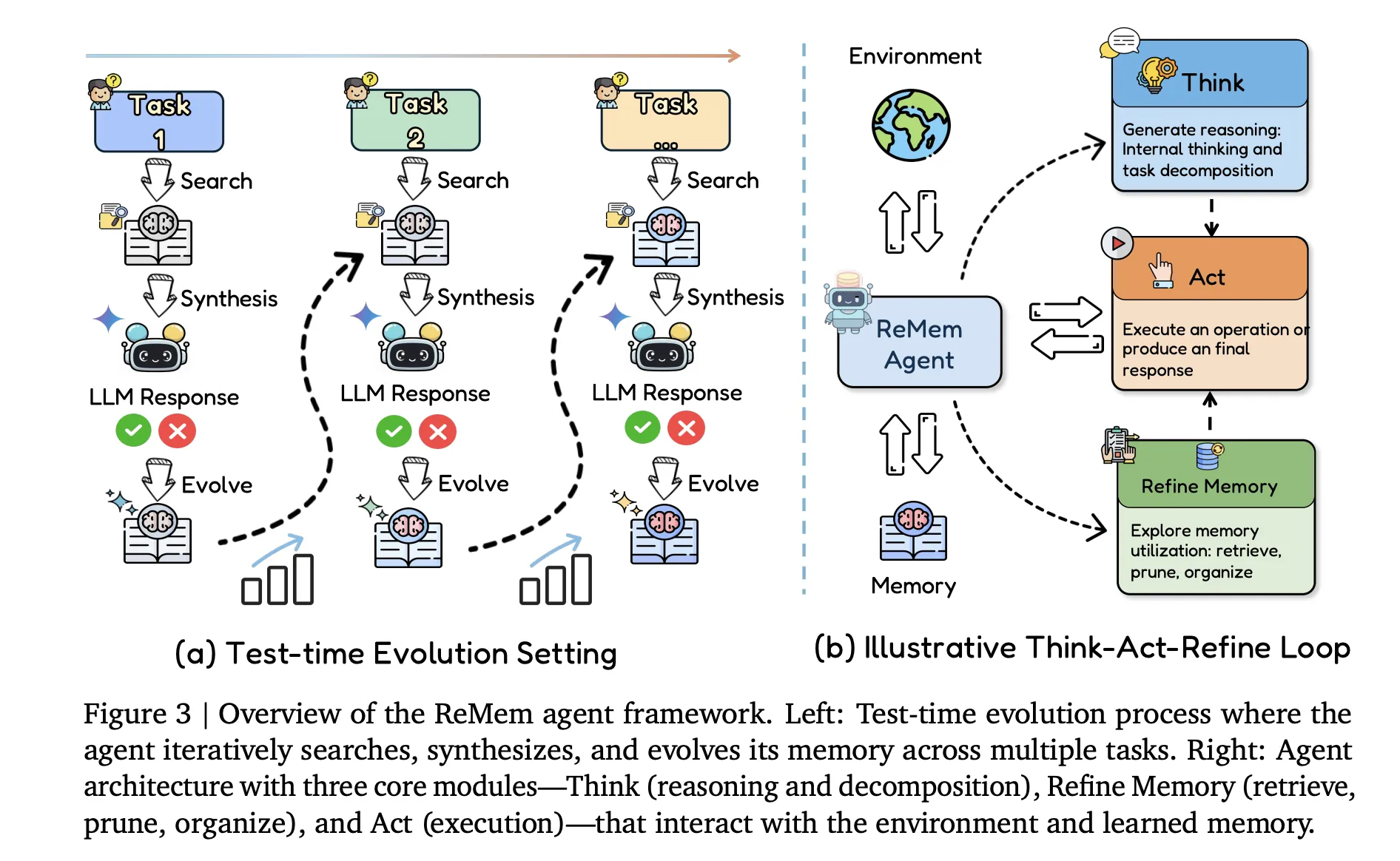
ReMem, Action Think Memory Refine
The main contribution on the agent side is ReMem, a pipeline allowing the agent to choose between three operations: Think, Act, and Refine. This loop creates a Markov decision process where the agent actively manages memory during inference, contrasting with traditional agents that treat memory as a fixed buffer.
Results on Reasoning, Tools, and Embodied Environments
The research team evaluated all methods on Gemini 2.5 Flash and Claude 3.7 Sonnet under a unified protocol, isolating memory architecture effects. Evolving memory methods like ReMem resulted in moderate gains across benchmarks.
In multi-turn environments, ReMem performed notably well, significantly enhancing task efficiency and success rates compared to history-based baselines.
Key Takeaways
- Evo-Memory allows agents to retrieve and integrate memory over time, moving beyond static conversational recall.
- The framework formalizes agents as a tuple ((F, U, R, C)) and includes over 10 memory modules evaluated on diverse datasets.
- ExpRAG serves as a minimal baseline for experience reuse, improving performance over traditional history-based approaches.
- ReMem introduces active memory management during inference, leading to notable improvements in accuracy and efficiency.
- Self-evolving memory methods help smaller models perform better without retraining.

Editorial Notes
Evo-Memory represents a significant advancement in evaluating self-evolving memory in LLMs. The study effectively showcases the potential for task-level experience reuse and the impact on agent performance without reliance on fixed memory structures.
Сменить язык
Читать эту статью на русском