NVIDIA AI представила KVzap: Эффективное обрезание кэша
Познакомьтесь с KVzap от NVIDIA - методом эффективного обрезания кэша с достижением 2x-4x сжатия.
Проблема с текущими размерами кэша
С увеличением длины контекста до десятков и сотен тысяч токенов кэш значений в трансформерах становится узким местом развертывания. Кэш хранит ключи и значения для каждого слоя и головы с формой (2, L, H, T, D). Например, для Llama1-65B кэш достигает около 335 ГБ при 128k токенов в bfloat16, что напрямую ограничивает размер пакета и увеличивает время на получение первого токена.
Техники архитектурного сжатия
Современные модели уже сжимают кэш по нескольким осям. Упаковка запросов делит ключи и значения между несколько запросами, достигая коэффициентов сжатия до 16 по различным моделям. Гибридные модели комбинируют стратегии внимания, чтобы уменьшить необходимость в полном кэше.
Однако эти методы не сжимают по оси последовательности. Разреженные методы получают только подмножество кэша, но все токены все равно потребляют память. Эффективное обслуживание длинных контекстов требует техник, которые удаляют записи кэша с минимальным воздействием.
KVpress: Экосистема методов обрезки
Проект KVpress от NVIDIA объединяет более двадцати техник обрезки в одной кодовой базе. Методы H2O, Expected Attention, DuoAttention и KVzip проверяются на их эффективность.
KVzip и KVzip+: Оракул оценок
KVzip является ведущим эталоном для обрезки кэша. Он определяет важные оценки для записей кэша на основе задачи копирования и вставки. Хотя KVzip+ улучшает эту оценку за счет корреляции весов внимания с фактическими взносами токенов, он создает трудности во время декодирования.
Введение KVzap: Суррогатная модель
KVzap представляет собой замену системы оценок на суррогатную модель, которая анализирует скрытые состояния. Она предсказывает оценки для ключевых значений, используя МЛП или простую линейную сеть, улучшая вычислительную эффективность.
Обучение используют с использованием 27k подсказок, получая около 1,2 миллиона пар для обучения. Для различных моделей корреляция между предсказанными и фактическими оценками варьируется от 0,63 до 0,77, что повышает предсказательную точность.
Техники вывода: Установление порогов и Скользящее окно
Во время вывода KVzap удаляет записи с низкими оценками, сохраняя скользящее окно из последних токенов. Этот подход позволяет динамически адаптироваться к плотности информации в подсказке, позволяя изменять коэффициенты сжатия для разных контекстов.
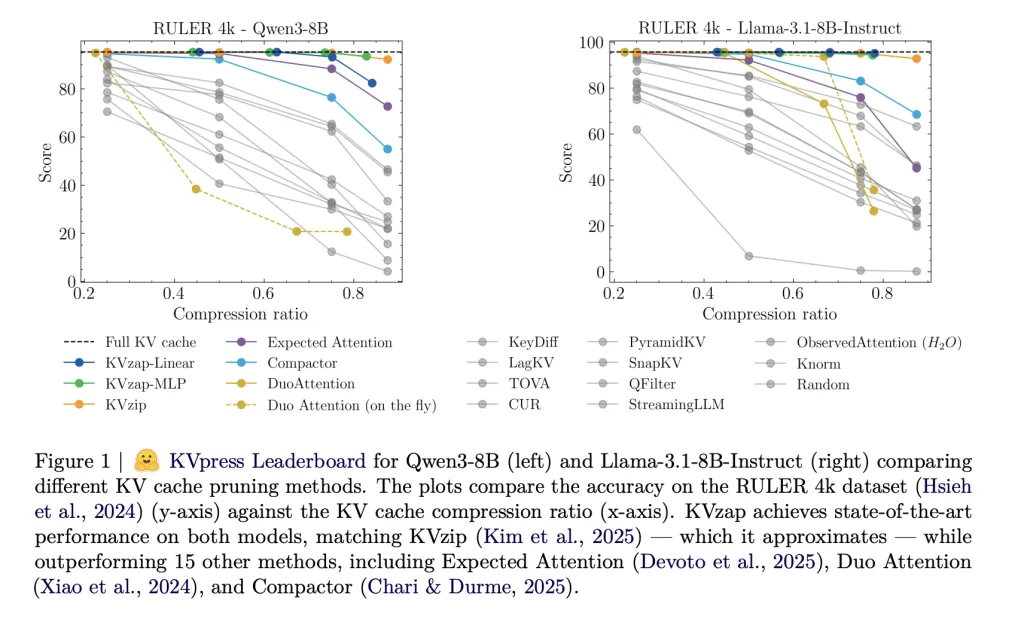
Оценка производительности по ключевым бенчмаркам
KVzap демонстрирует впечатляющую производительность на бенчмарках RULER и LongBench, достигая значительных коэффициентов сжатия, близких к полным кэша. Он также превосходит по заданиям AIME25, сохраняя точность даже при значительных уровнях сжатия.
Ключевые выводы
- KVzap заменяет KVzip+, предсказывая оценки важности KV от скрытых состояний с минимальными вычислительными затратами.
- Достигает круглой корреляции варьируя от 0,6 до 0,8, что достаточно для эффективного ранжирования кэша.
- Динамическая адаптация к плотности информации позволяет изменять коэффициенты сжатия для различных подсказок.
- На нескольких бенчмарках KVzap достигает заметного сжатия кэша, сохраняя точность и демонстрируя свою ценность в практических приложениях.
- Дополнительные вычисления минимальны, достигая всего 1,1% для варианта МЛП, и KVzap реализован в открытом программном обеспечении KVpress с готовыми контрольными точками на Hugging Face.
Switch Language
Read this article in English