Рекурсивные языковые модели: Революция в контексте ИИ
Узнайте, как РЛМы преодолевают ограничения в производительности моделей.
Понимание рекурсивных языковых моделей
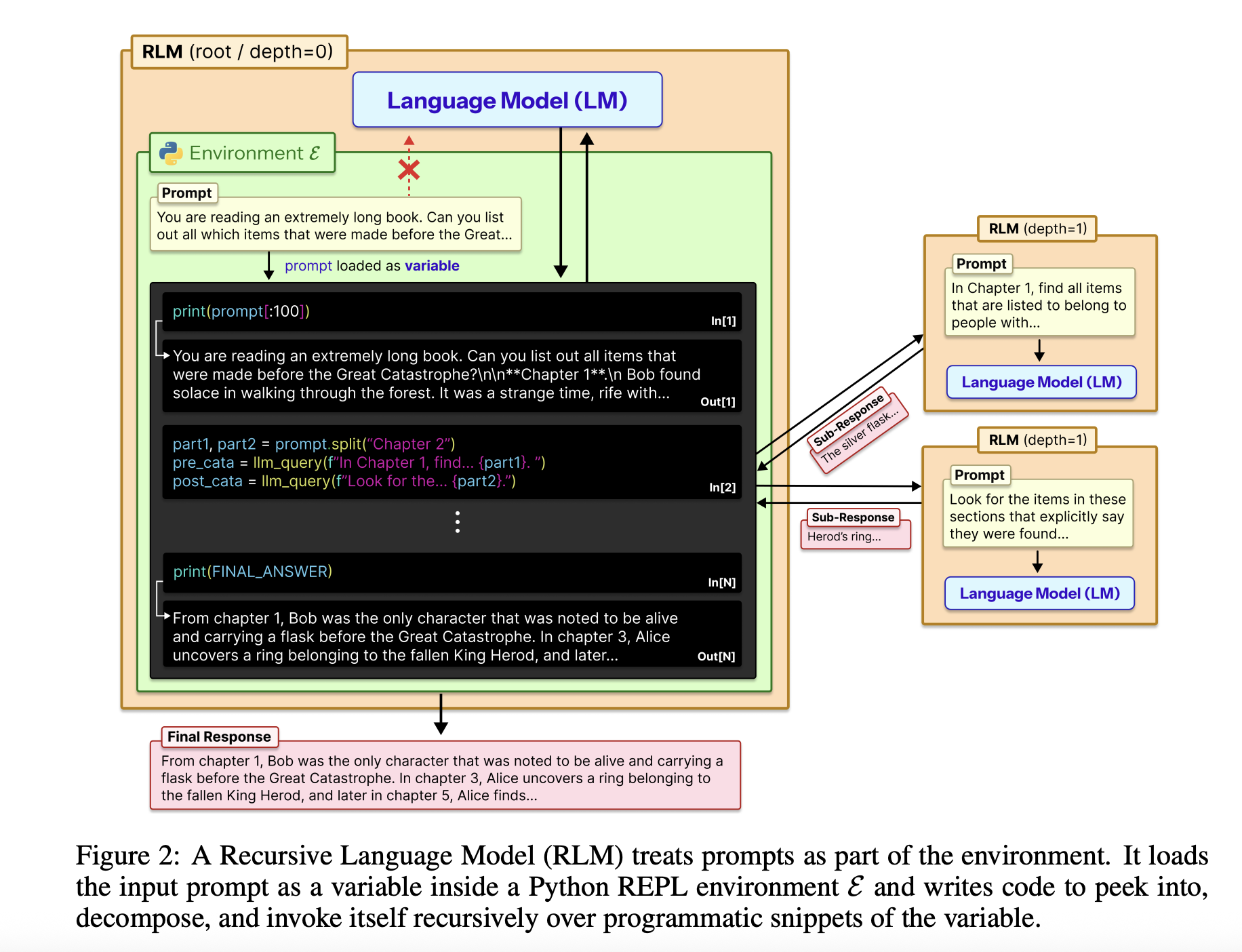
Рекурсивные языковые модели (РЛМы) стремятся преодолеть обычный компромисс между длиной контекста, точностью и стоимостью больших языковых моделей. Вместо того чтобы заставлять модель прочитать огромный ввод за один раз, РЛМы рассматривают ввод как внешнюю среду и позволяют модели решать, как к ней обращаться через код, а затем рекурсивно вызывать себя на меньших частях.
Основы
Весь ввод загружается в Python REPL как одна строка. Корневая модель, например, GPT-5, никогда не видит эту строку непосредственно в своем контексте. Вместо этого она получает системную подсказку, объясняющую, как читать срезы переменной, писать вспомогательные функции, создавать подвызываемые LLM и комбинировать результаты. Окончательный текстовый ответ возвращается, сохраняя внешний интерфейс, идентичным стандартной точке завершения общения.
Дизайн РЛМ использует REPL как управляющую плоскость для длинного контекста. Среда, обычно написанная на Python, предоставляет инструменты, такие как срезы строк, поиск по регексу и вспомогательные функции, такие как llm_query для вызова меньших моделей, например, GPT-5-mini. Корневая модель пишет код, который сканирует, разбивает и обобщает внешний контекст, сохраняя промежуточные результаты для построения окончательного ответа шаг за шагом. Эта структура делает размер ввода независимым от окна контекста модели, превращая обработку длинного контекста в задачу синтеза программы.
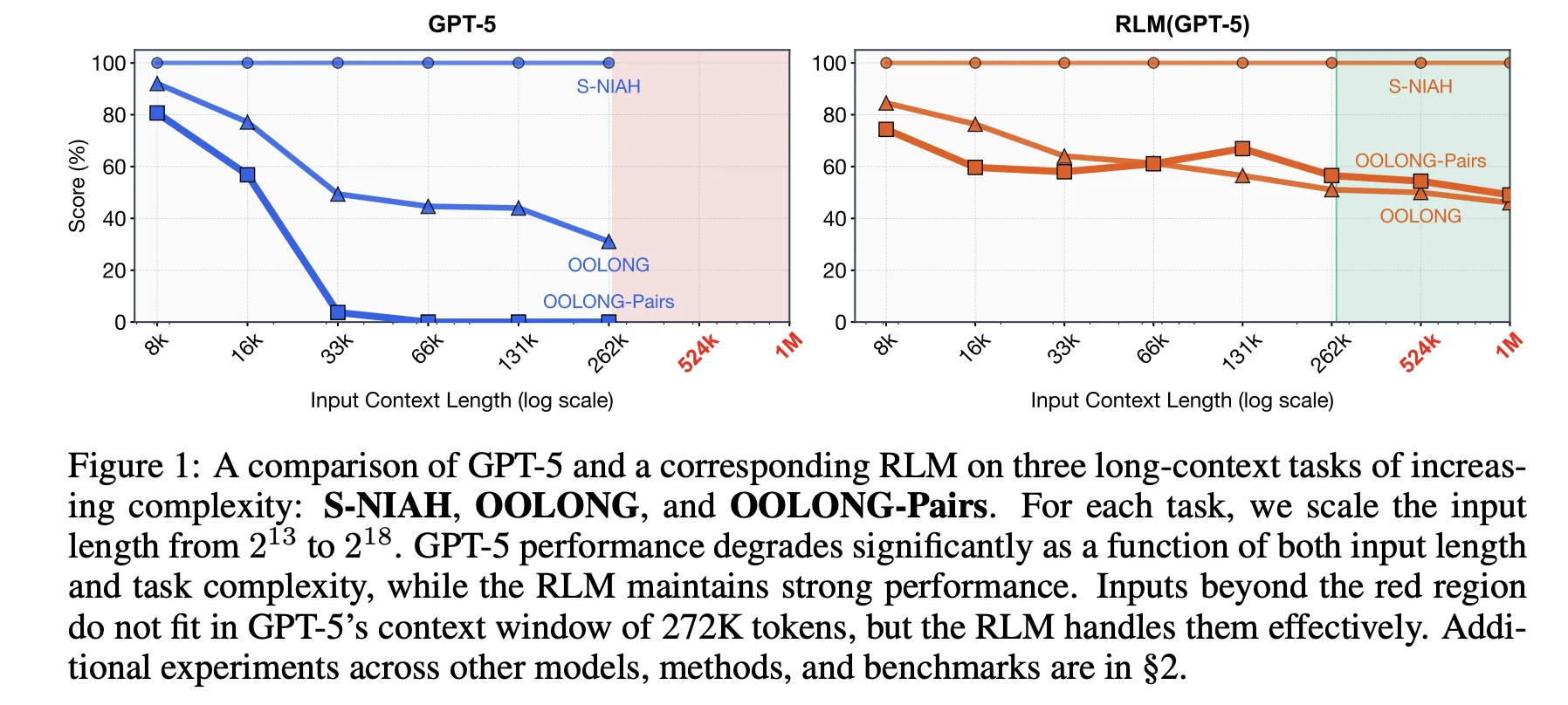
Оценка РЛМ
Исследовательская работа оценивает РЛМы по четырем бенчмаркам длинного контекста с различными вычислительными структурами: S-NIAH, BrowseComp-Plus, OOLONG и OOLONG Pairs. Эти задачи подчеркивают необходимость как длины контекста, так и глубины рассуждений.
РЛМы превосходят прямые вызовы LLM и обычные агенты длинного контекста. Например, в GPT-5 на CodeQA для вопросов по длинным документам модель достигла 62.00 точности с рекурсией, в то время как агент с обобщением набрал 41.33.
На самом сложном бенчмарке, OOLONG Pairs, РЛМы достигли заметных улучшений с F1 на уровне 58.00. Эти результаты подчеркивают важность как REPL, так и рекурсивных подвызываемых вызовов в плотных квадратных задачах.
Эффективность в различных бенчмарках
Бенчмарк BrowseComp-Plus демонстрирует значительное расширение контекста. РЛМ сохраняет хорошую производительность даже при обработке 1,000 документов, достигая приблизительно 91.33 точности, в то время как стандартный GPT-5 деградирует при увеличении количества документов.
Исследовательская работа также анализирует траектории РЛМ. Модель сначала осматривает первые несколько тысяч символов и использует фильтрацию по ключевым словам с помощью регулярных выражений. Для более сложных запросов она разбивает контекст на части и выполняет рекурсивные вызовы на каждом фрагменте.
Реализация Prime Intellect
Команда Prime Intellect разработала RLMEnv, интегрируя эту концепцию в свою систему проверки. Основной РЛМ использует Python REPL, в то время как под LLM обрабатывают тяжелые операции, такие как веб-поиски. Это вводит функцию llm_batch для параллельного выполнения подзапросов.
Prime Intellect оценивает RLMEnv в нескольких средах, таких как DeepDive и Math Python, достигая повышения надежности и производительности, особенно в условиях длинного контекста.
Ключевые выводы
- РЛМы переосмысляют управление контекстом: РЛМы обрабатывают ввод как строку Python в REPL, работая через код, а не путем прямого поглощения токенов.
- Значительное расширение контекста: РЛМы могут эффективно обрабатывать ввод, превышающий 10 миллионов токенов, достигнув длины, не имеющей аналогов в традиционных моделях.
- Превосходство в производительности по сравнению с обычными методами: Варианты РЛМ демонстрируют более высокую точность и результаты F1 по сравнению со стандартными вызовами моделей и системами извлечения.
- Ценность REPL: Даже варианты, использующие только REPL, повышают производительность в некоторых задачах, хотя для значительных улучшений требуются полные реализации РЛМ.
- Операционализированность от Prime Intellect: RLMEnv от Prime Intellect обеспечивает эффективную и надежную работу с комплексными контекстами, минимизируя деградацию производительности.
Switch Language
Read this article in English