Recursive Language Models Transform LLM Context Handling
Discover how RLMs break the trade-off between context length and model performance.
Understanding Recursive Language Models
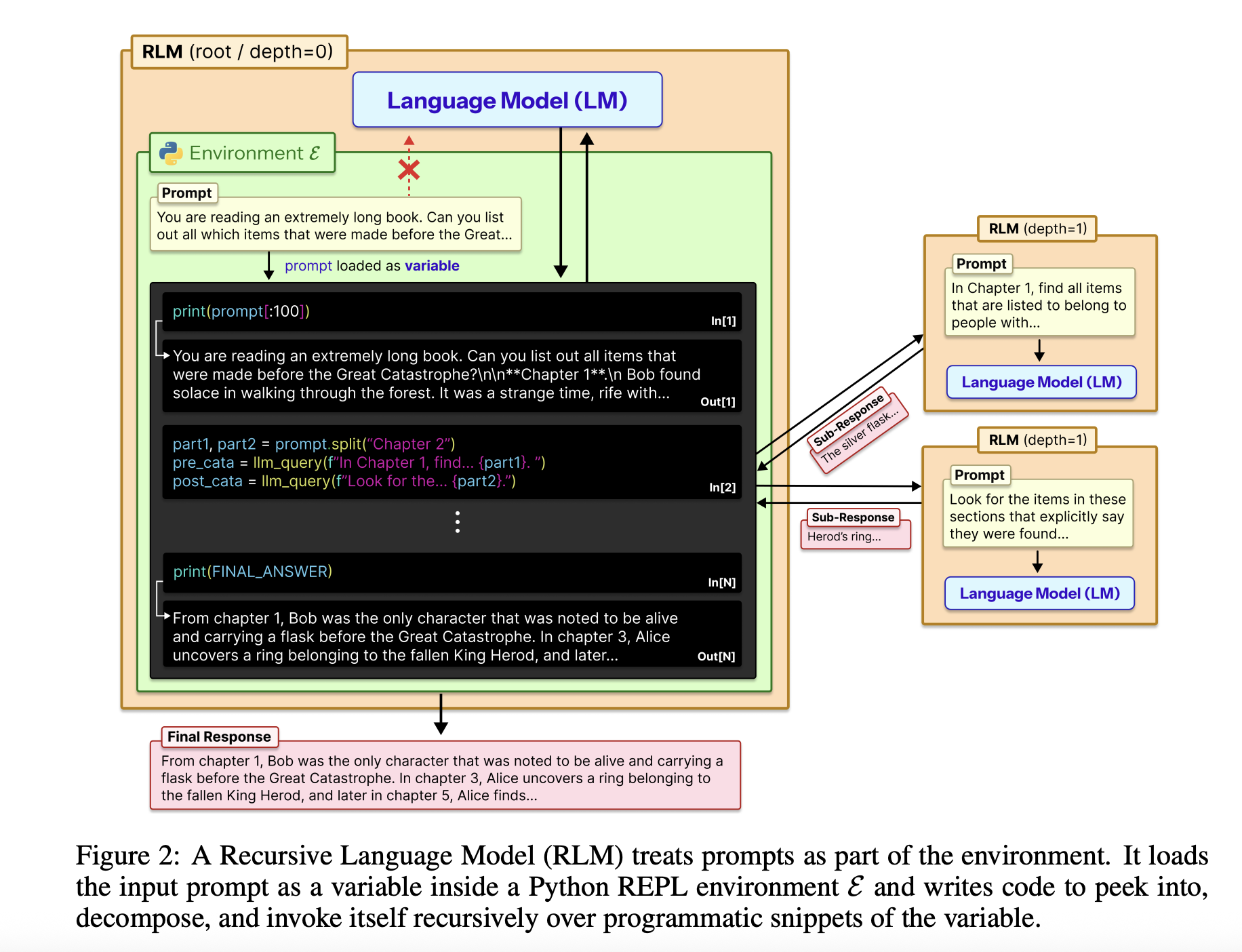
Recursive Language Models (RLMs) aim to break the usual trade-off between context length, accuracy, and cost in large language models. Instead of forcing a model to read a giant prompt in one pass, RLMs treat the prompt as an external environment and allow the model to decide how to inspect it with code, then recursively call itself on smaller pieces.
The Basics
The full input is loaded into a Python REPL as a single string variable. The root model, for example, GPT-5, never sees that string directly in its context. Instead, it receives a system prompt explaining how to read slices of the variable, write helper functions, spawn sub LLM calls, and combine results. The final text answer is returned, keeping the external interface identical to a standard chat completion endpoint.
RLM design uses the REPL as a control plane for long context. The environment, usually written in Python, exposes tools like string slicing, regex search, and helper functions like llm_query for smaller model instances, e.g., GPT-5-mini. The root model writes code to scan, partition, and summarize the external context, storing intermediate results to build the final answer step by step. This structure makes prompt size independent from the model’s context window, turning long context handling into a program synthesis problem.
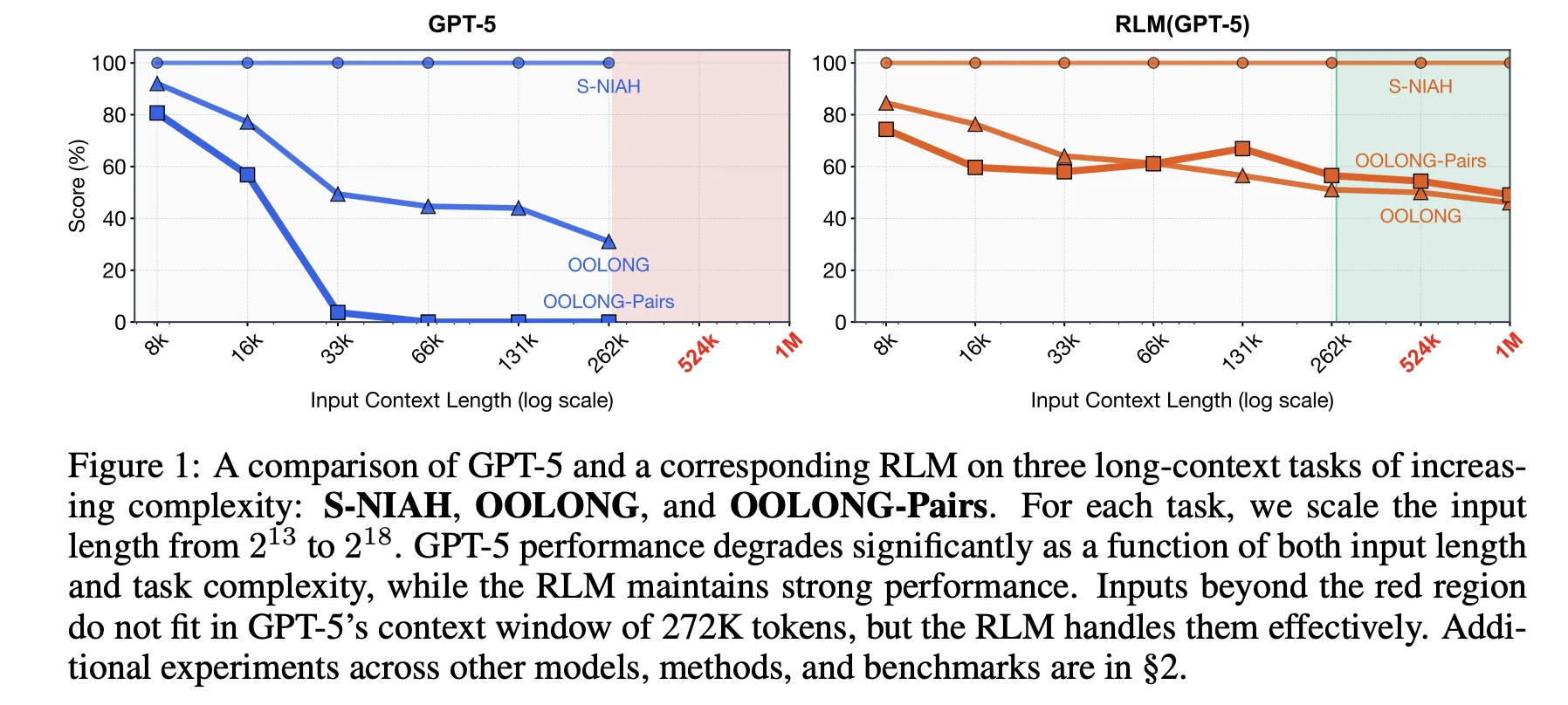
Evaluating RLMs
The research paper evaluates RLMs on four long context benchmarks with various computational structures: S-NIAH, BrowseComp-Plus, OOLONG, and OOLONG Pairs. These tasks highlight the need for both context length and reasoning depth.
RLMs outperform direct LLM calls and common long context agents. For instance, in GPT-5 on CodeQA for long document question answering, the model achieved a 62.00 accuracy with recursion, while a summarization agent scored 41.33.
On the hardest benchmark, OOLONG Pairs, RLMs attained noticeable gains with F1 scores peaking at 58.00. These results underscore the importance of both the REPL and recursive sub-calls in dense quadratic tasks.
Performance in Various Benchmarks
The BrowseComp-Plus benchmark demonstrates significant context extension. RLM maintains strong performance even when given 1,000 documents, achieving approximately 91.33 accuracy while standard GPT-5 degrades as the document count increases.
The research paper also analyzes RLM trajectories. The model initially inspects the first few thousand characters and employs regex filtering to concentrate on relevant lines. For complex queries, it partitions the context and performs recursive calls on each chunk.
Prime Intellect's Implementation
The Prime Intellect team has developed RLMEnv, integrating this concept into their verifier stack. The main RLM uses a Python REPL, while sub LLMs handle heavy operations like web searches. It introduces the llm_batch function for fan-out subqueries in parallel.
Prime Intellect evaluates RLMEnv across multiple environments like DeepDive and Math Python, achieving improved robustness and performance, especially in long context conditions.
Key Takeaways
- RLMs redefine context management: RLMs treat the entire prompt as a Python string in a REPL, processing it through code instead of direct token ingestion.
- Extending context significantly: RLMs can handle prompts exceeding 10M tokens effectively, reaching lengths unparalleled in traditional models.
- Performance superiority over conventional methods: RLM variants demonstrate higher accuracy and F1 scores compared to standard model calls and retrieval systems.
- Value of REPL: Even REPL-only variants enhance performance in certain tasks, though full RLM implementations are required for substantial gains.
- Operationalization by Prime Intellect: Prime Intellect’s RLMEnv enables effective and robust handling of complex contexts, ensuring minimal degradation in performance.
Explore the detailed research paper for more insights and technical specifications.
Сменить язык
Читать эту статью на русском