Google Unveils T5Gemma 2: Cutting-Edge Multimodal Models
Explore Google's T5Gemma 2, an advanced encoder-decoder model family emphasizing multimodality and long context for developers.
Overview
Google has published T5Gemma 2, a family of open encoder-decoder Transformer checkpoints built by adapting Gemma 3 pretrained weights into an encoder-decoder layout, then continuing pretraining with the UL2 objective. The release is pretrained only, intended for developers to post-train for specific tasks, and Google explicitly notes it is not releasing post-trained or IT checkpoints for this drop.
Enhancements in T5Gemma 2
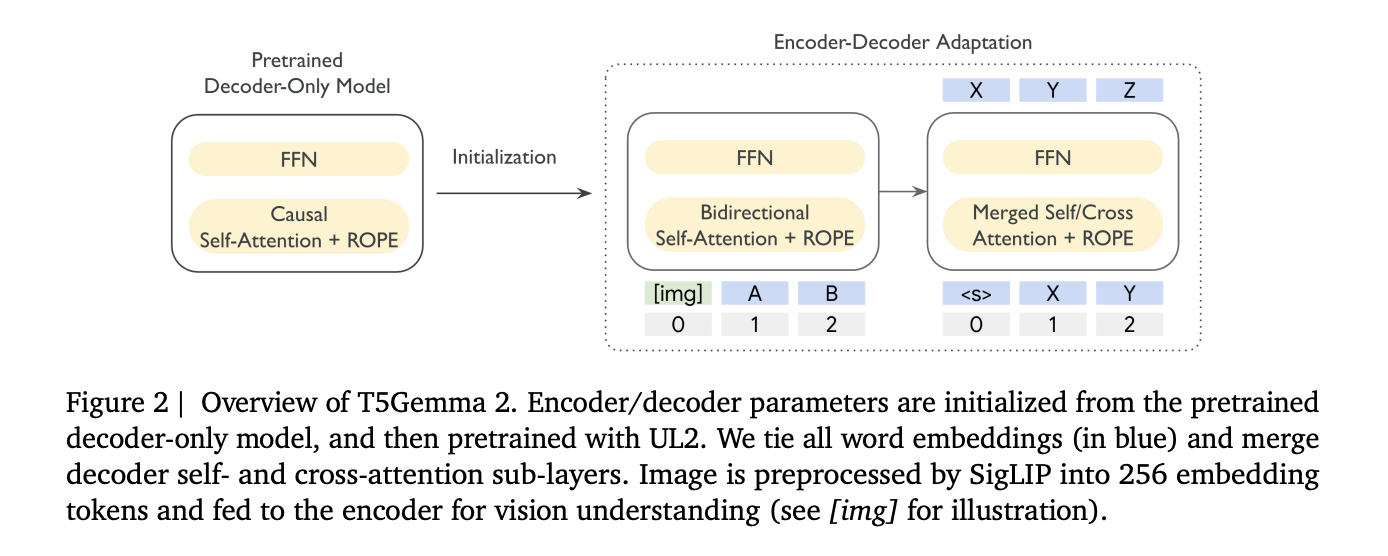
T5Gemma 2 serves as an encoder-decoder counterpart to Gemma 3, retaining the same foundational building blocks while introducing two structural changes for enhanced small model efficiency. The models inherit Gemma 3 features important for deployment, notably multimodality, long context up to 128K tokens, and extensive multilingual coverage, supporting over 140 languages.
What Google Actually Released?
The release includes three pretrained sizes: 270M-270M, 1B-1B, and 4B-4B, where this notation indicates the encoder and decoder are of the same size. Excluding the vision encoder, the research team reports approximate totals of 370M, 1.7B, and 7B parameters. The multimodal setup includes a 417M parameter vision encoder alongside embeddings for both encoder and decoder.
Efficient Encoder-Decoder without Starting from Scratch
T5Gemma 2 follows the adaptation model from T5Gemma, initializing an encoder-decoder from a decoder-only checkpoint and then adapting using UL2. This unique division allows the encoder to read the complete input bidirectionally, while the decoder focuses on autoregressive generation,which greatly assists in long context tasks requiring relevant evidence retrieval from large inputs.
Key Efficiency Changes
- Tied word embeddings: Shared embeddings across encoder, decoder, and output layers reduce redundancy without significant quality loss.
- Merged attention: This innovation simplifies the decoder by merging self-attention and cross-attention into a single operation, facilitating easier initialization and demonstrating parameter savings with minimal quality drop.

Multimodal Capabilities
T5Gemma 2 is multimodal by reusing Gemma 3’s vision encoder, keeping it frozen during training. The vision tokens are fed into the encoder where they can interact with text tokens within a unified contextual representation. The system is structured as an image-text-to-text pipeline to facilitate efficient validation in multimodal scenarios.
Enabling Long Contextualization
The 128K context window is attributed to Gemma 3’s alternating local and global attention mechanisms. The design includes a repeating pattern of 5 local sliding window layers followed by a global layer, reducing key-value cache growth which supports the feasibility of long contexts within smaller model footprints.
Training Setup Details
Models were pretrained on 2T tokens with a training setup that includes a batch size of 4.2M tokens, cosine learning rate decay with 100 warmup steps, and checkpoint averaging over the last 5 checkpoints.
Key Takeaways
- T5Gemma 2, an encoder-decoder family adapted from Gemma 3, continues with UL2 methodology.
- Google exclusively released pretrained checkpoints; no post-trained variants are included.
- Utilizes a SigLIP vision encoder to manage multimodal inputs effortlessly.
- Incorporates pivotal efficiency changes such as tied embeddings and merged attention.
- Supports long context processing up to 128K tokens thanks to inherited attention designs.
Сменить язык
Читать эту статью на русском