Nanbeige4-3B: Прорыв в обучении токенов
Как модель с 3B параметрами достигает разума на уровне 30B благодаря инновационным методам обучения.
Оценка новой парадигмы в обучении моделей
Может ли модель с 3B параметрами обеспечить разум на уровне 30B за счет исправления рецепта обучения, а не увеличения параметров? Лаборатория LLM Nanbeige в Boss Zhipin выпустила Nanbeige4-3B, семейство малых языковых моделей с 3B параметрами, обученных с акцентом на качество данных, расписание обучения, дистилляцию и обучение с подкреплением.
Исследовательская команда предлагает два основных контрольных пункта: Nanbeige4-3B-Base и Nanbeige4-3B-Thinking, оценив настроенную модель рассуждений по сравнению с контрольными точками Qwen3 от 4B до 32B.
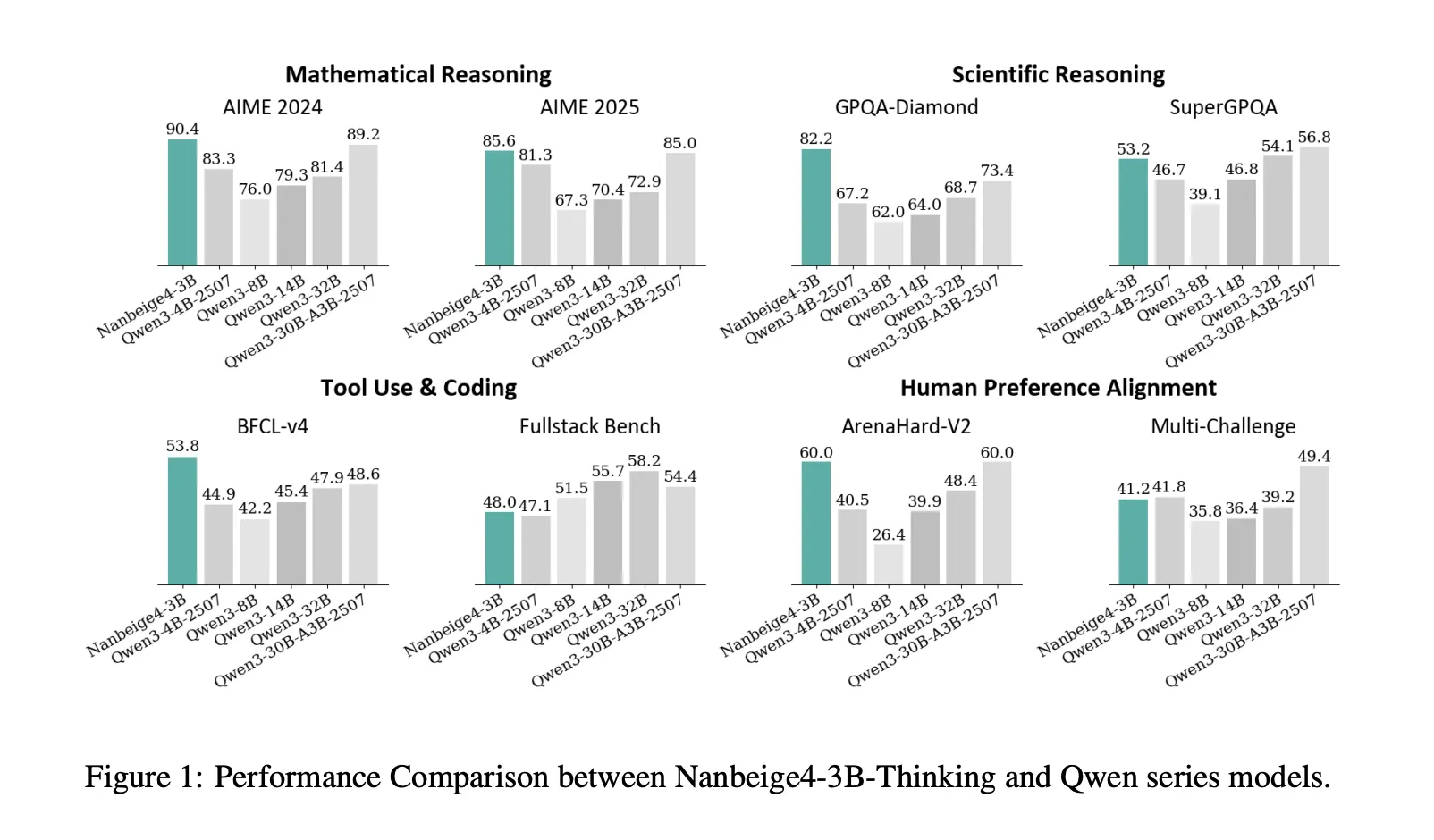
Метрики производительности
На AIME 2024 модель Nanbeige4-3B-2511 показала 90.4, тогда как Qwen3-32B-2504 — 81.4. На GPQA-Diamond Nanbeige4-3B-2511 показала 82.2, опередив 64.0 для Qwen3-14B-2504 и 68.7 для Qwen3-32B-2504. Эти результаты демонстрируют, как модель с 3B параметрами может превосходить значительно более крупные модели.

Тренировочный пайплайн: Инновационные техники
Гибридная фильтрация данных и дополнительная выборка
Для предобучения команда объединяет многомерное тегирование с оценкой на основе схожести, создавая тренировочную корпуcу из 23T токенов. Этот процесс включает фильтрацию до 12.5T токенов высококачественных данных и выборку более качественного подмножества в 6.5T, демонстрируя явное отличие от традиционных методов обучения.
FG-WSD: Новый подход к планированию данных
Nanbeige4-3B представляет Точные Спецификации Устойчивого Флота (FG-WSD), акцентируя внимание на использовании более качественных данных на поздних этапах обучения. Этот подход акцентирует внимание на качестве учебного процесса, а не на количестве.

В абляционных исследованиях модель демонстрирует значительное улучшение в таких бенчмарках, как GSM8K, что подтверждает эффективность FG-WSD.
Многоэтапная супервайзингированная настройка (SFT)
Обучение в многоэтапной системе SFT улучшает способности рассуждения. Низкий старт начинается с выборок QA, сосредоточенных на математике и коде, за которым следует общее SFT, направленное на общие задачи рассуждения. Этот многоаспектный тренировочный подход гарантирует повышенную производительность в задачах рассуждения.
Сравнительная таблица: Производственные метрики
| Бенчмарк, метрика | Qwen3-14B-2504 | Qwen3-32B-2504 | Nanbeige4-3B-2511 | |---------------------------------|-----------------|-----------------|-------------------| | AIME2024, avg@8 | 79.3 | 81.4 | 90.4 | | GPQA-Diamond, avg@3 | 64.0 | 68.7 | 82.2 | | Arena-Hard-V2, avg@3 | 39.9 | 48.4 | 60.0 |
Ключевые выводы из исследования
- Способности к рассуждениям: Модель демонстрирует, что более компактные конфигурации могут эффективно конкурировать с более крупными моделями в области рассуждений благодаря тщательно разработанным стратегиям обучения.
- Методы оценки: Строгая методология усредненного отбора обеспечивает надежность метрик точности.
- Курируемые данные обучения приносят плоды: Делиберативное планирование качественных данных в этапах обучения существенно влияет на общие производственные метрики.
Дополнительные идеи можно почерпнуть в полном исследовательском документе и в весах модели. Прогрессы, достигнутые через модель Nanbeige4-3B, показывают большие надежды для будущих разработок в области ИИ и рассуждений.
Switch Language
Read this article in English