Qwen3-TTS: Open Multilingual TTS Suite with Real-Time Latency
Explore Alibaba Cloud's Qwen3-TTS, a multilingual TTS suite with voice control and real-time response.
Overview
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack: voice cloning, voice design, and high-quality speech generation.
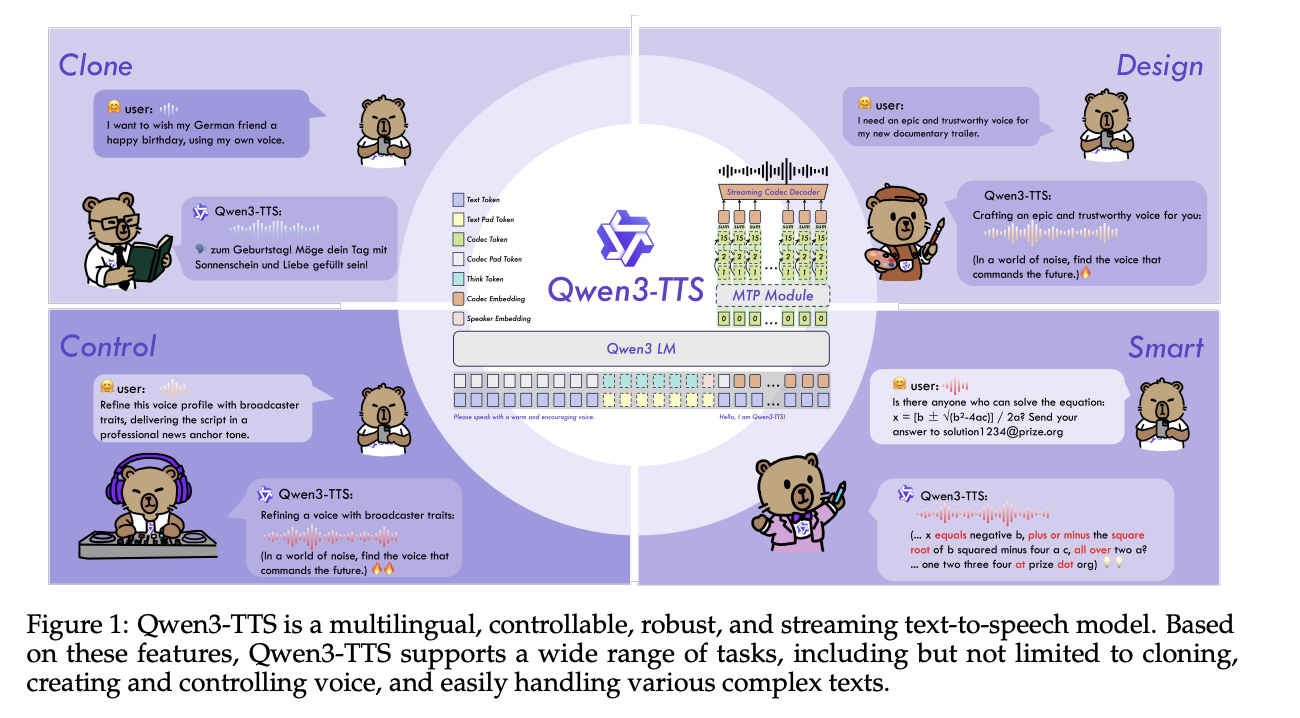
Model Family and Capabilities
Qwen3-TTS uses a 12Hz speech tokenizer and offers two language model sizes—0.6B and 1.7B—packaged into five models. These support ten languages, including Chinese, English, Japanese, and Russian. Notably, the VoiceDesign model allows for free-form voice creation directly from natural language descriptions.
Architecture, Tokenizer, and Streaming Path
The dual-track architecture predicts discrete acoustic tokens and manages alignment/control signals. Operating at 80 ms per token with a 12.5 fps tokenizer, it excels in both quality and efficiency, achieving low latency in streaming.
Alignment and Control
Utilizing a multi-stage alignment pipeline, Qwen3-TTS fine-tunes target speaker variants while maintaining the core capabilities of the general model. This includes support for instruction-following in a ChatML format.
Benchmarks and Multilingual Performance
The model showcases state-of-the-art performance on multilingual datasets, achieving the lowest Word Error Rate (WER) in six out of ten languages tested. Additionally, it excels in zero-shot voice cloning.
Key Takeaways
- Open Source: Licensed under Apache 2.0, covering multiple tasks in a single stack.
- Real-Time Streaming: The efficient tokenizer enables sub-120 ms first packet latency.
- Variety of Models: Offers diverse functionalities from cloning to custom voice design.
- Superior Multilingual Quality: Consistently high speaker similarity and low error rates across several languages.
Сменить язык
Читать эту статью на русском