DeepSeek AI Unveils DeepSeekMath-V2 for Olympiad Proofs
Explore the capabilities of DeepSeekMath-V2, scoring 118/120 on Putnam 2024.
Overview of DeepSeekMath-V2
DeepSeek AI has launched DeepSeekMath-V2, an open weights large language model optimized for natural language theorem proving with self-verification. Built on DeepSeek-V3.2-Exp-Base, this model comprises a 685B parameter mixture of experts, making it available for deployment under an Apache 2.0 license on Hugging Face.
Evaluation Highlights
DeepSeekMath-V2 scored 118 out of 120 points on Putnam 2024, achieving gold level scores on IMO 2025 and CMO 2024 using scaled test time compute.
Addressing Final Answer Limitations
Most math models utilize reinforcement learning to reward only the final answer. However, DeepSeek's team identified crucial issues with this approach:
- Correct numeric answers can stem from flawed reasoning.
- Problems like olympiad proofs demand complete arguments, rather than singular numeric solutions.
DeepSeekMath-V2 emphasizes proof quality over mere answer accuracy. The model assesses proof completeness and logical coherence as its primary learning signals.
Verifier-First Training Approach
The system begins with a verifier-first design. The research team trains a language model verifier that assesses the problem and proposed proof, providing both analysis and a score on a scale of 1.
Initial reinforcement learning data originates from Art of Problem Solving contests, encompassing 17,503 proof-required problems. Human experts label proofs according to established criteria, ensuring rigor and completeness.
Introducing the Meta Verifier
To prevent exploitation of the verification process, a meta verifier was incorporated. This verifies the original problem and the verifier's analysis, scoring the faithfulness and consistency of the evaluation. Enhanced training with GRPO enables the meta verifier to elevate average quality ratings significantly.
Self Verifying Proof Generation
After strengthening the verifier, the team trains a proof generator that produces solutions along with self-analysis, rewarding performance based on several criteria, including agreement with the verifier's assessment.
Scaling Verification with Auto Labeling
To streamline the labeling process of high-quality problems, an automatic labeling pipeline is developed, leveraging scaled verification methods that validate candidate proofs based on multiple independent analyses.
Competition Performance Insights
On various competitive fronts, DeepSeekMath-V2 consistently surpasses benchmarks:
- It solved 5 of 6 IMO 2025 problems at a gold medal level.
- It achieved 4 full solutions and partial credit on CMO 2024.
- Record score of 118 out of 120 on Putnam 2024, outshining the best human score of 90.
Summary of Innovations
- The 685B parameter model emphasizes both self verification and proof quality, deployed as open weights.
- Its novel framework combines a verifier and meta verifier to highlight logical integrity over mere correctness.
- This methodology allows DeepSeekMath-V2 to excel in math competitions, solidifying its position as a leading model in math problem solving.
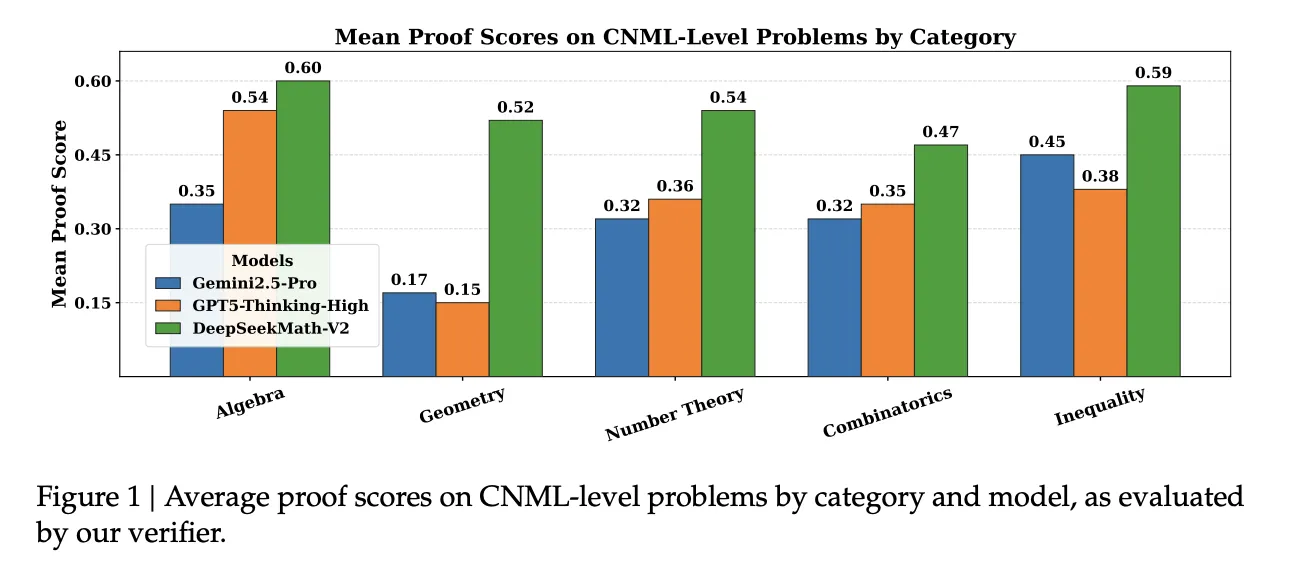
Editorial Perspective
DeepSeekMath-V2 marks a pivotal progression in self-verifiable mathematical reasoning, bridging the gap between correct answers and sound logic. Its deployment showcases a practical approach to tackling high-level competition problems.
Сменить язык
Читать эту статью на русском